
Юрий Ветров уже 7 лет выпускает дайджест продуктового дизайна. Следующий выпуск будет шестидесятым, и этот обзор, с одной стороны, возможность посмотреть на интересные факты, а с другой, отметить тот труд который делает Юра.
Прежде чем ответить на вопрос как прочитать все выпуски, я немного расскажу зачем это делать.
Помимо праздного любопытства, многие из нас находятся в состоянии когда их просто захлестывает поступающей информацией. Нужно тратить около часа в день на чтение различных новых статей или хотя бы раз в месяц разгребать ссылки из дайджеста. Времени на все не хватает и новости проносятся мимо нас и завтра нас ждет очередная порция новостей.
В недавнем обсуждении в сообществе UX club посвященном этой проблеме, можно увидеть из комментариев, что проблема действительно имеет место, и решают все ее по-разному.
Но что если перестать смотреть на эти ссылки как на список отобранных материалов. Что если попытаться увидеть смысл во всей этой информационной структуре. Можно ли увидеть этот поток как например можно увидеть спектрограмму звука? Понять какая у него “мелодия”. Как она менялась со временем? Эти вопросы были передо мной около года назад, когда я понял что хочу проанализировать все дайджесты продуктового дизайна.
Сразу скажу что не на все эти вопросы я ответил, к каким то приблизился, но желание поделится тем что уже есть сейчас, перевесило желание получить “матрицу”. Для людей мало знакомых с content discovery это такой термин который включает массу способов извлечения из какого-то массива данных полезной информации. Довольно сложно описать все эти термины в нескольких словах, если хотите то почитайте вот этот лонгрид. Конкретно для этой работы использовался сервис Watson Alchemy от IBM который позволяет анализировать контент и немного самописных скриптов на питоне, визуализация была построена на dc.js и d3.js.
Анализ источников
За 7 лет в 59 дайджестов вошло 7875 ссылок
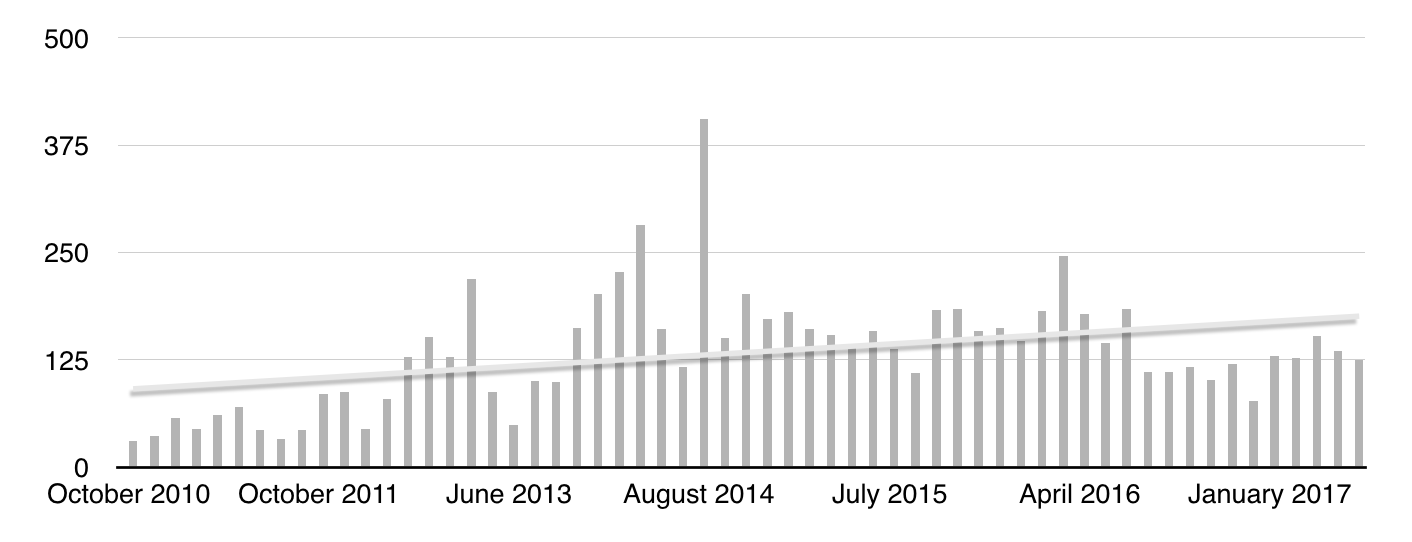 Количество материалов по дайджесту (сверху наложен линейный тренд)
Количество материалов по дайджесту (сверху наложен линейный тренд)
За эти годы менялся подход к рубрикам, какие то видоизменялись, появлялись новые и с начальных 9 все пришло к 18.
Количество рубрик увеличилось в 2 раза
 Диаграмма показывает наполняемость рубрики материалами в каждом выпуске
Диаграмма показывает наполняемость рубрики материалами в каждом выпуске
Типы материалов (disclaimer есть некоторая неточность в алгоритме который определяет сайт это или статья, но процент ошибок не очень большой)
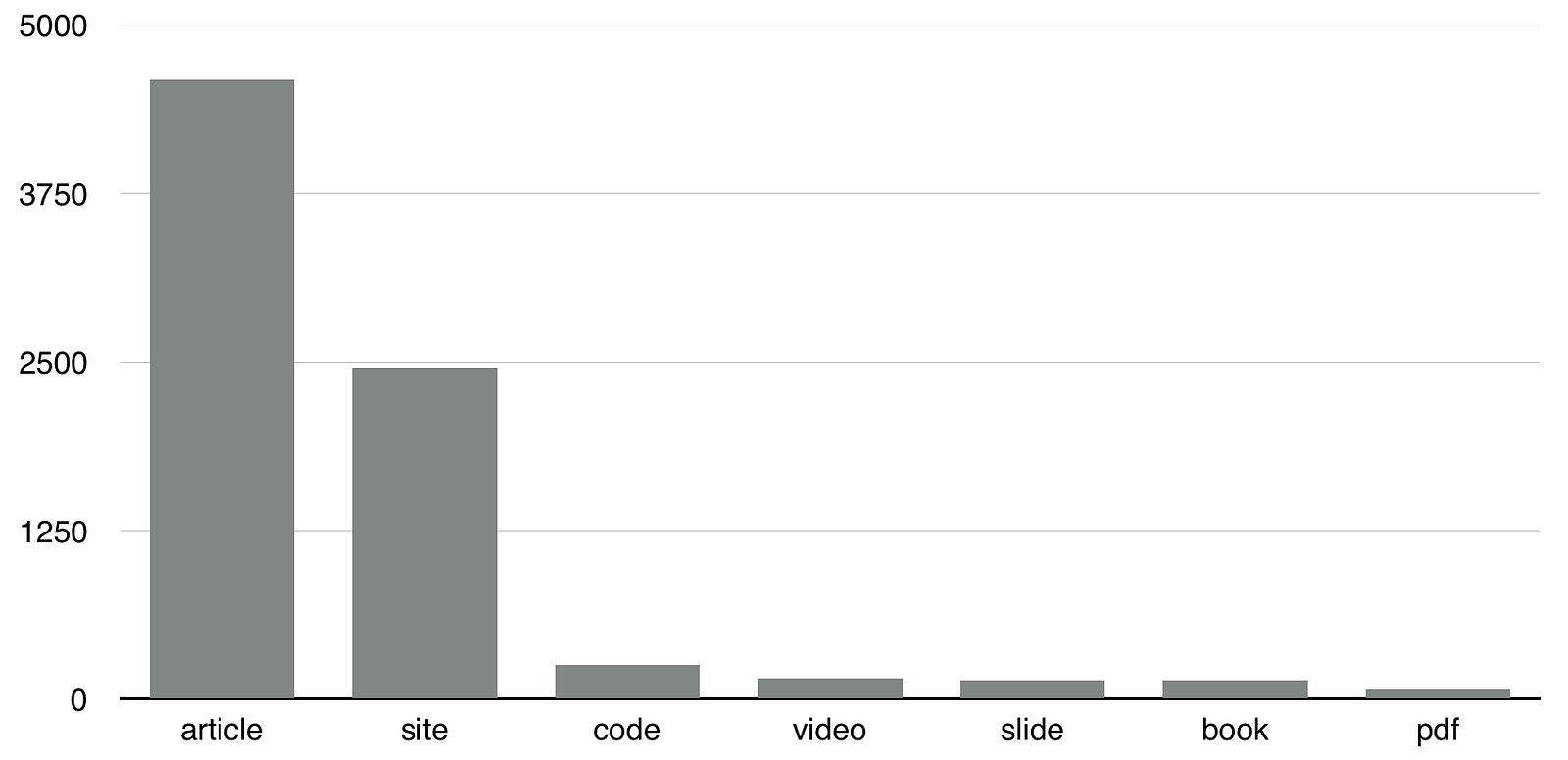 Количество материалов по типу
Количество материалов по типу
7% материалов на русском языке
Большая часть ссылок была с этих сайтов
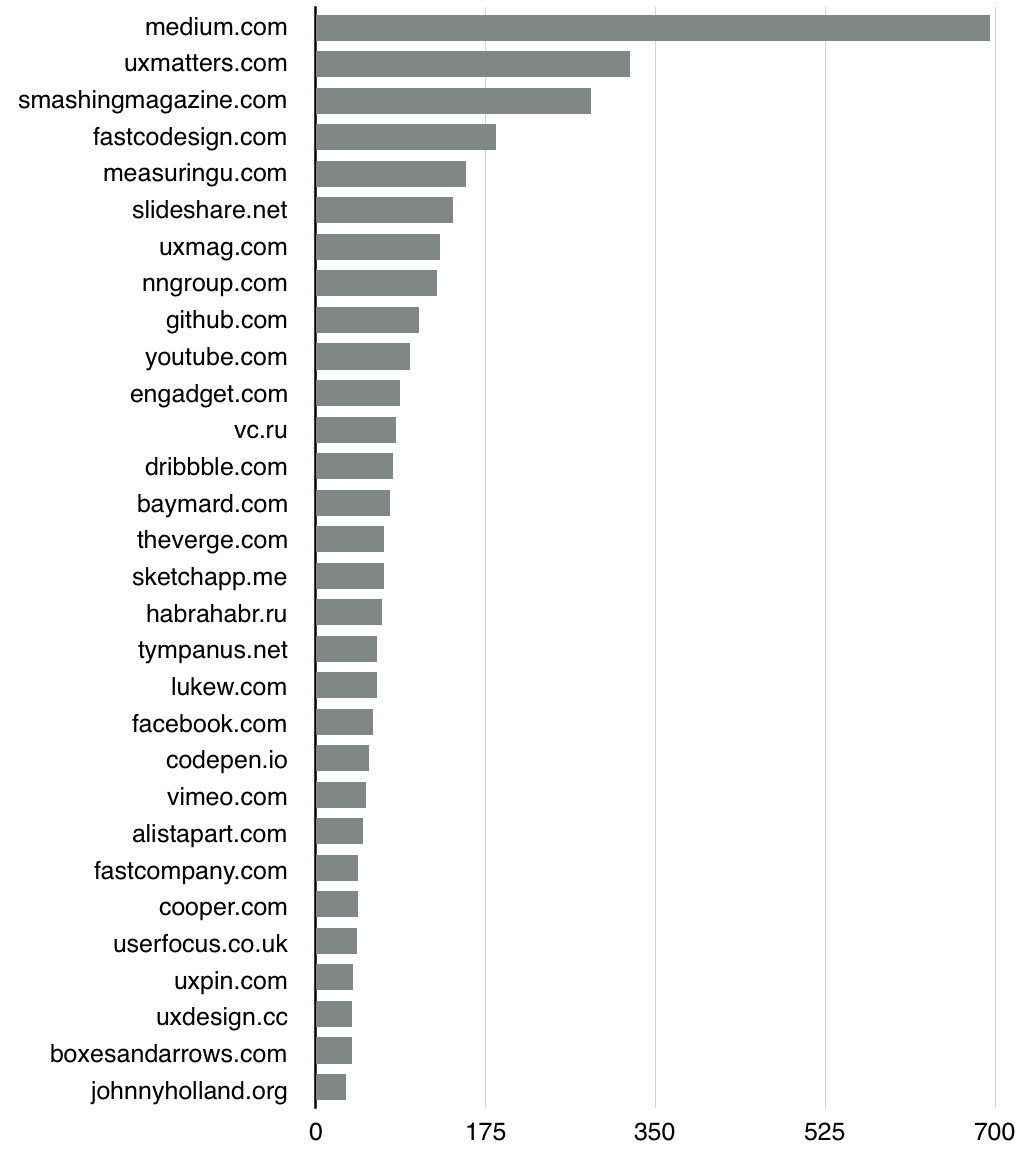 Количество материалов по домену
Количество материалов по домену
Контент анализ
Watson Alchemy позволяет анализировать тексты по различным параметрам, например находить ключевые слова, находить упоминания имен, дат и цифр.
Стив Джобс почти в два раза опережает Нильсена.
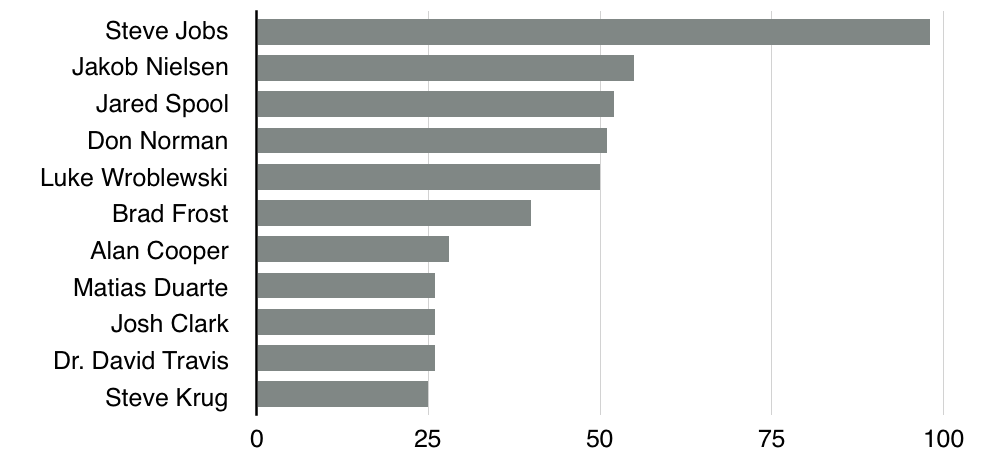 Количество материалов по персоне
Количество материалов по персоне
А Google обходит Apple.
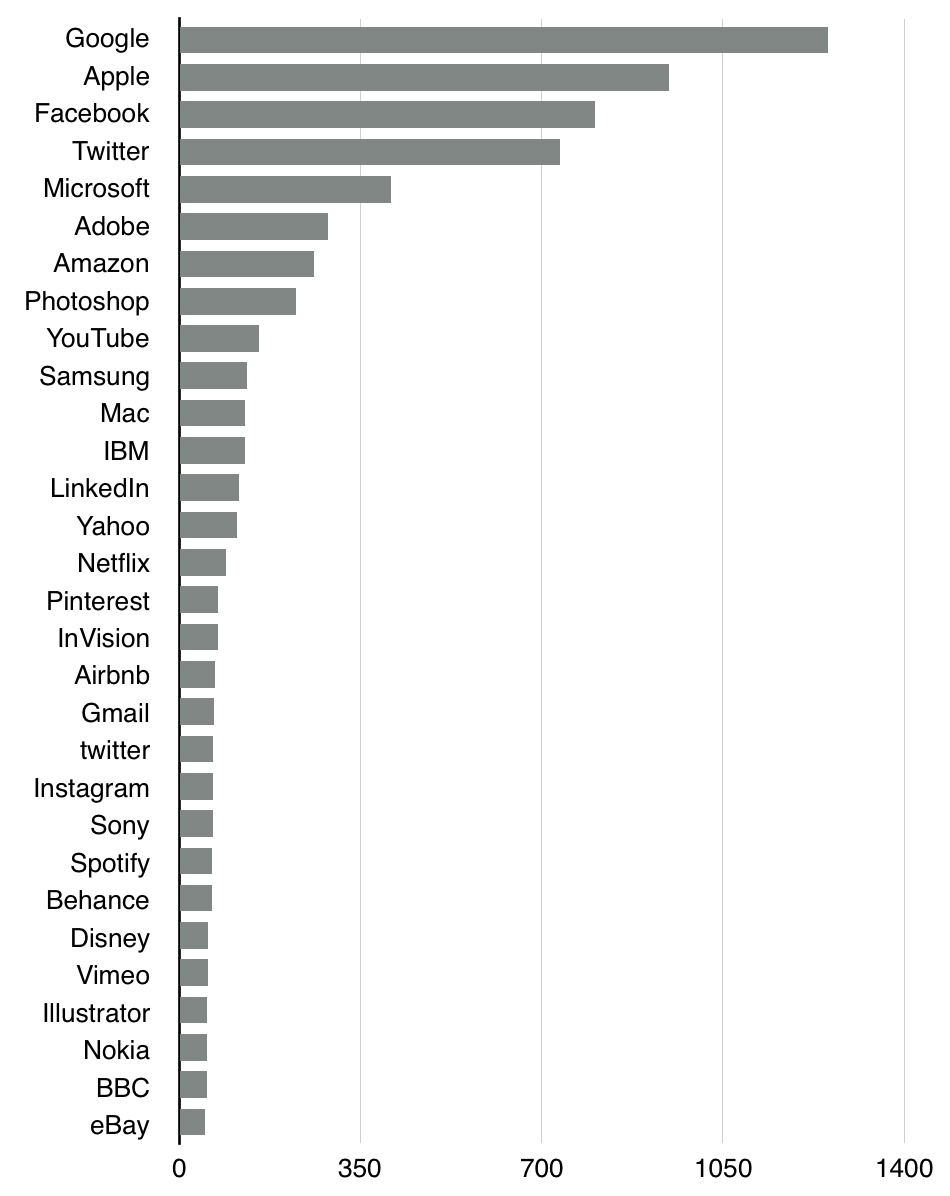 Количество материалов по компании
Количество материалов по компании
Авторы очень любят округлять.
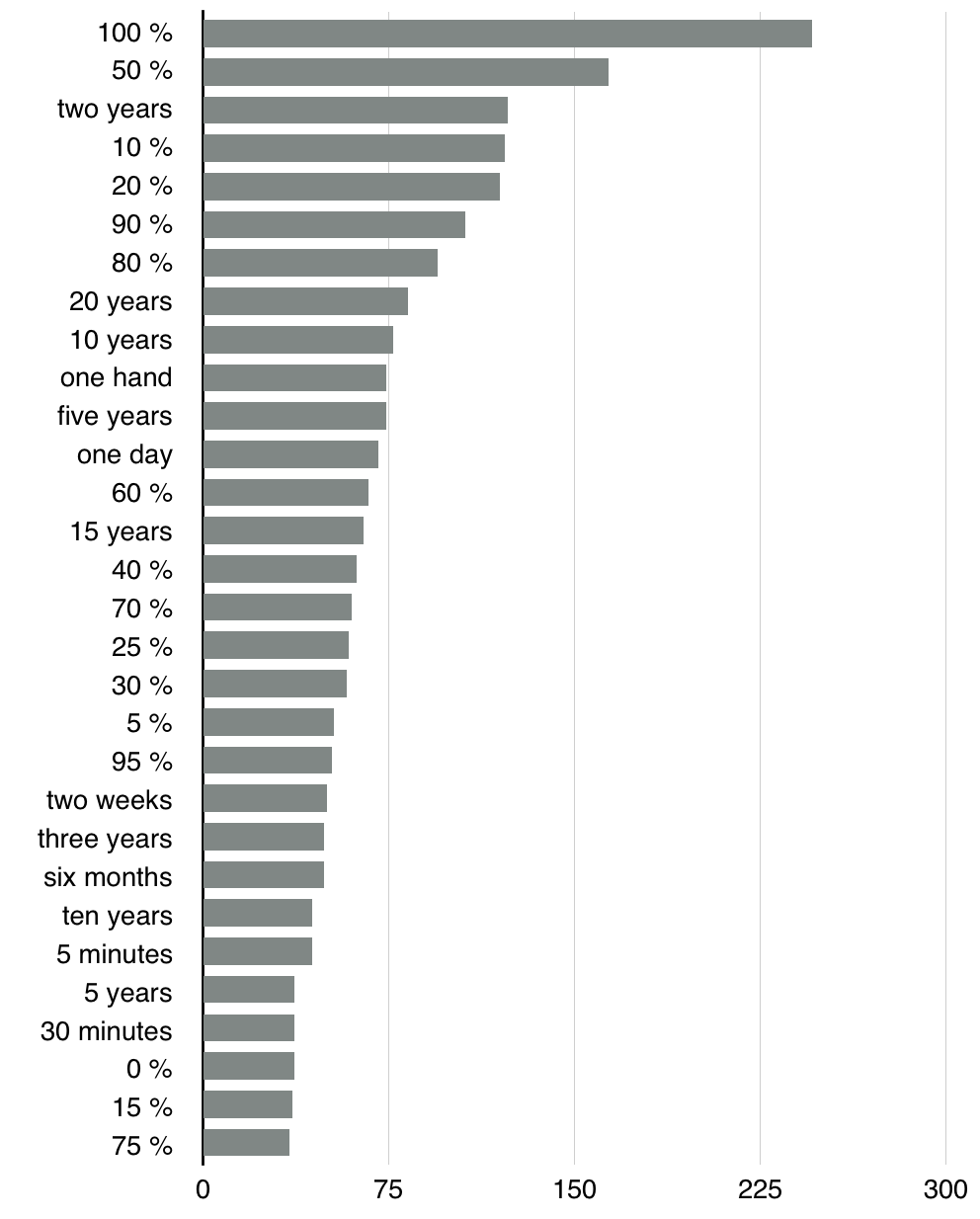 Количество материалов по “цифрам”
Количество материалов по “цифрам”
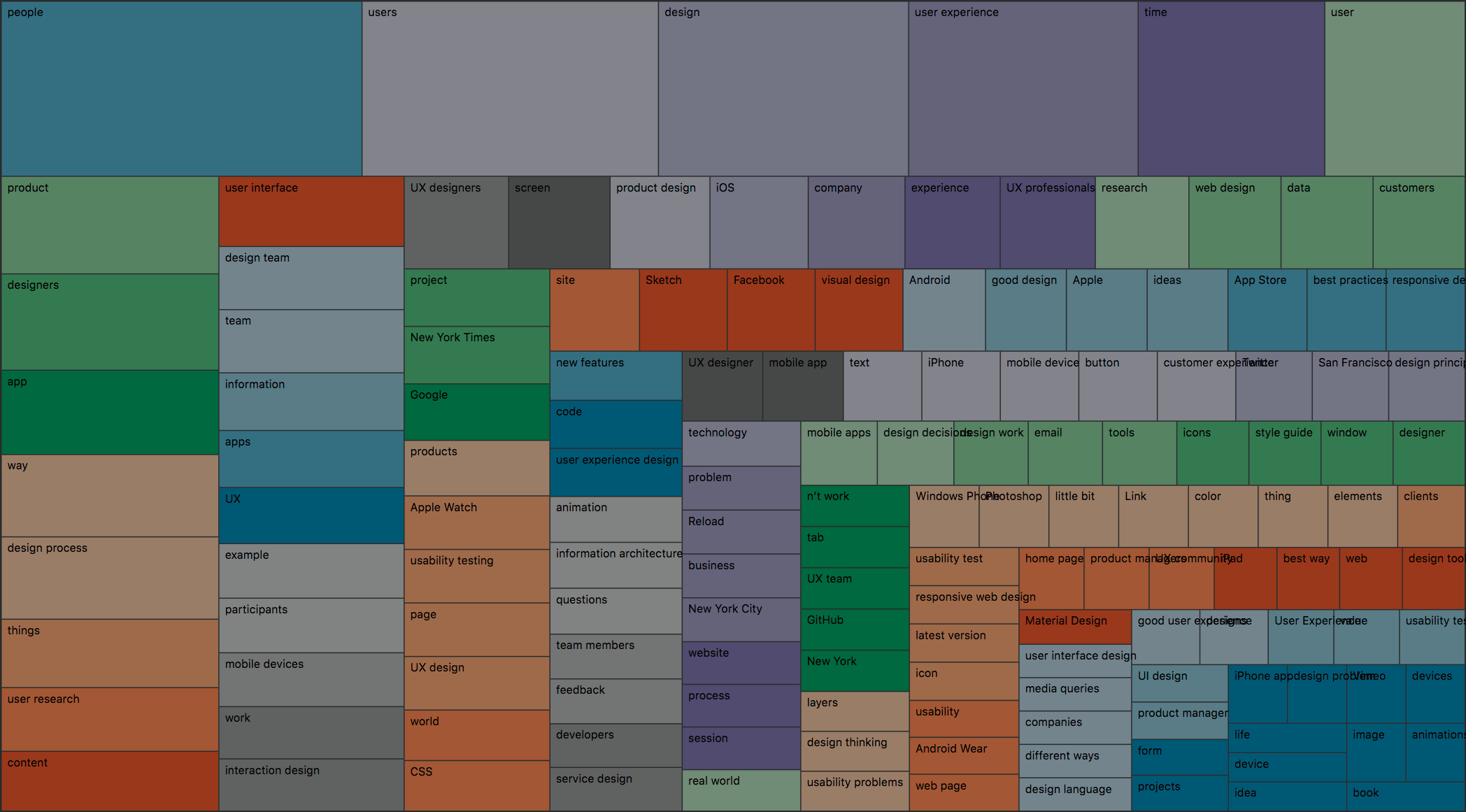 Диаграмма ключевых слов (топ 150)
Диаграмма ключевых слов (топ 150)
И теперь приятное
Благодаря современным технологиям по визуализации данных, с этого момента, интерактивная версия отчета доступна на сайте uxbuzzwords.ru для анализа и просмотра. Кликая на фильтры можно сузить выборку, в том числе и по времени, с помощью таймлайна который расположен снизу.
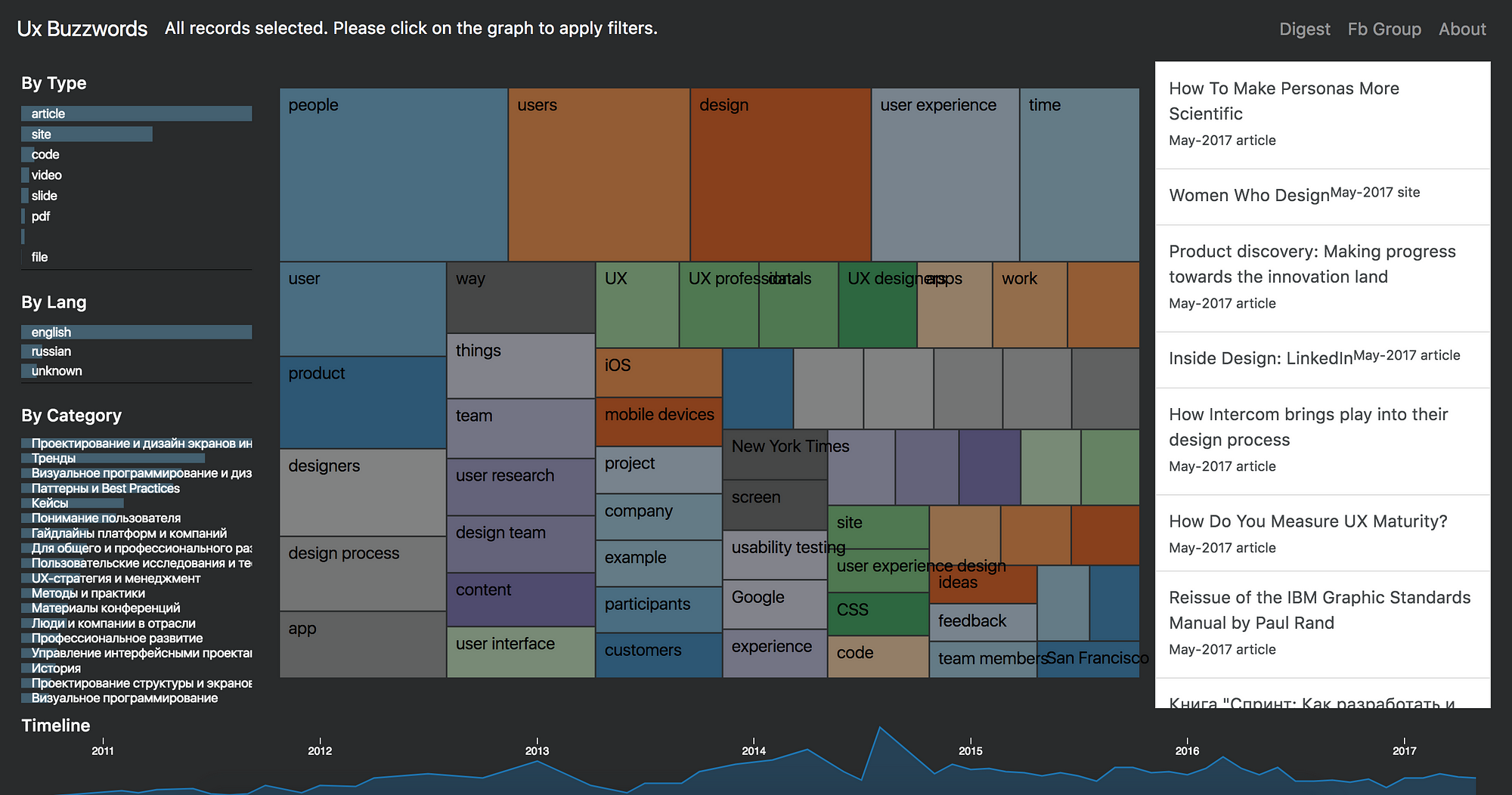 uxbuzzwords.ru
uxbuzzwords.ru