
Мне было интересно проверить насколько сервисы для автоматизированного распознавания аудиозаписей пригодны для расшифровки (или транскрибирования) интервью записанных в неидеальных условиях.
Я протестировал одно интервью записанное с громкой связи через сервис sonix.ai (его обычно чаще всего рекомендуют UX-ресерчеры) и speech-to-text API от яндекса и гугла.
Если коротко, то все молодцы, но Яндекс получше, а API позволяет делать расшифровку в 10 раз дешевле.
Введение
Отдельно нужно поговорить про то, зачем делать полную расшифровку интервью, ведь обычно она нафиг никому не нужна и вместо неё, пишутся главные темы в виде тезисов, которые далее сводятся по всем респондентам для оценки общей картины.
Можно выделить несколько причин:
-
Бывает что расшифровка это обязательное требование заказчика;
-
Если вместо расшифровки вы пишите выжимку, то это ваша интерпретация, текст интервью подсвечивает то, как были заданы вопросы, таким образом повышает прозрачность полученной информации;
-
Часто в интервью всплывают моменты, которые не относятся напрямую к теме исследования, но могут быть полезны — текст интервью позволяет систематизировать информацию и легко ее искать в будущем;
-
Текст дает возможность быстрой навигации по записи, что в некоторых случаях ускоряет процесс анализа, когда можно сразу пройтись по интересующим темам и пропустить второстепенные.
Варианты не делать расшифровку вручную
-
Аутсорс
-
Автоматизация
Качество у аутсорса приближается к 100%, но страдает скорость. У автоматических алгоритмов наоборот, результат доступен через секунды, но качество, сильно зависит от многих параметров, например качества записи, чистоты речи и так далее.
Исследование
Я выбрал из архивов одно неудавшееся короткое интервью по поликому на громкой связи, записанное на диктофон iphone. И прогнал его через sonix.ai и speech-to-text API от яндекса и гугла.
Ниже показан фрагмент таблица со сравнением (только проблемные места)
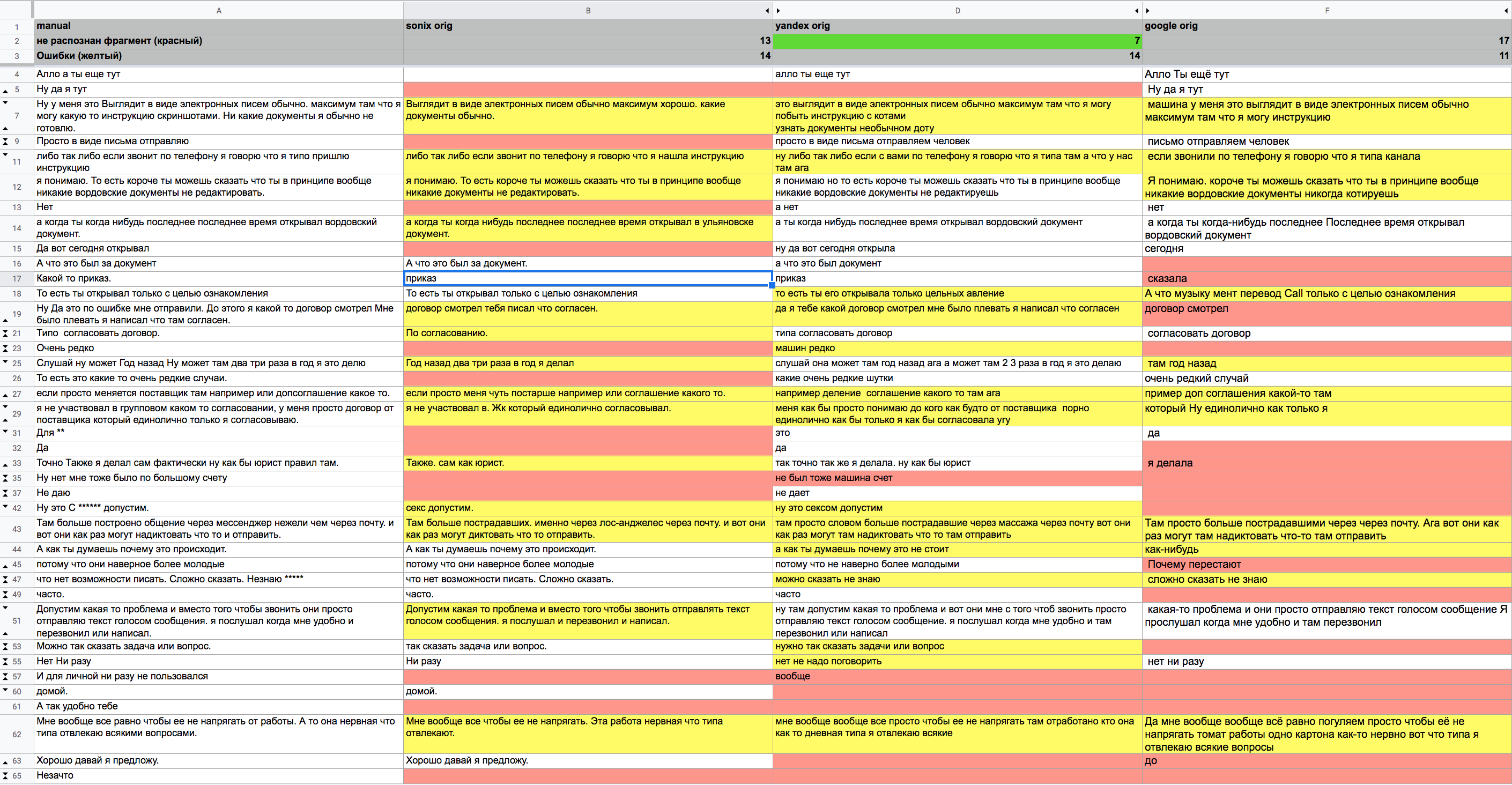
А здесь можно найти полный файл: comparison spechtotext.xlsx sonix, yandex, googledocs.google.com
Выводы
По итогу получилось что алгоритм Яндекса справился лучше, так как у него было меньше всего моментов связанных с не распознаванием фрагментов от респондента. А это с моей точки зрения важнее, чем помарки в распознавании.
Все алгоритмы очень хорошо распознали фрагменты интервьюера. Ошибки были у всех примерно в одинаковом количестве. На мой взгляд, качество всех алгоритмов довольно неплохое, и для записей в лучшем качестве будет еще меньше проблем.
Сколько стоит автоматическое распознавание 1 часа аудио
-
Sonix 620р 10$
-
Google Speechkit Api 89р 1.44$
-
Yandex Speechkit Api 36р 0.58$
*1$ — 62р
P.S.
Если у вас есть бюджет, то используйте sonix.ai (это моя реферальная ссылка) он быстро работает, поддерживает популярные форматы аудио, есть настраиваемый словарь, редактор транскрипта.
А если денег нет, то потратьте вечер чтобы разобраться с тем, как делать запросы к speech-to-text API и сможете получить тот же результат, но на порядок дешевле.
Как использовать API
Необходимо зарегистрироваться, подключить сервис хранилища данных, настроить сервисный аккаунт.
Для выполнения запросов я использовал python. В целом схема рабочая, я периодически ее использую, но нужно разобраться.
Если нужно, то могу написать подробную инструкцию и выложить ссылки на скрипты, если интересно дайте знать.